Google también señala que este tipo de marca de agua funciona mejor cuando hay mucha “entropía” en la distribución LLM, lo que significa múltiples candidatos válidos para cada token (por ejemplo, “Mi fruta tropical favorita es [mango, lychee, papaya, durian]En situaciones en las que el programa LLM “siempre devuelve la misma respuesta a un mensaje determinado”, como preguntas fácticas básicas o modelos configurados a una “temperatura” más baja, la marca de agua es menos efectiva.
Google dice que SynthID se basa en herramientas similares de marcas de agua de texto de IA anteriores al ofrecer lo que llama un enfoque de muestreo de torneos. Durante el ciclo de generación de tokens, este enfoque ejecuta cada token candidato potencial a través de una ronda en forma de arco de varias etapas, donde cada ronda es “juzgada” por una función de marca de agua aleatoria diferente. Sólo el ganador final de este proceso llega a la salida final.
¿Pueden decir que es Folger?
Obviamente, cambiar el proceso de selección del token LLM con una marca de agua arbitraria puede tener un impacto negativo en la calidad del texto generado. Pero en su investigación, Google explica que SynthID puede “deformarse” a nivel de símbolos individuales o secuencias cortas de texto, dependiendo de la configuración específica utilizada en el algoritmo del torneo. Google dice que otras configuraciones pueden aumentar la “distorsión” causada por la herramienta de marca de agua y al mismo tiempo aumentar la detectabilidad de la marca de agua.
Para probar cómo cualquier posible distorsión de la marca de agua afectaría la calidad percibida y la utilidad de la salida de LLM, Google enruta una “parte aleatoria” de las consultas de Gemini a través del sistema SynthID y las compara con sus contrapartes sin marca de agua. En un total de 20 millones de respuestas, los usuarios otorgaron un 0,1 por ciento más de calificaciones de “excelente” y un 0,2 por ciento menos de calificaciones de “excelente” a las respuestas con marcas de agua, lo que muestra apenas una diferencia medible por humanos en una amplia gama de interacciones reales de LLM.
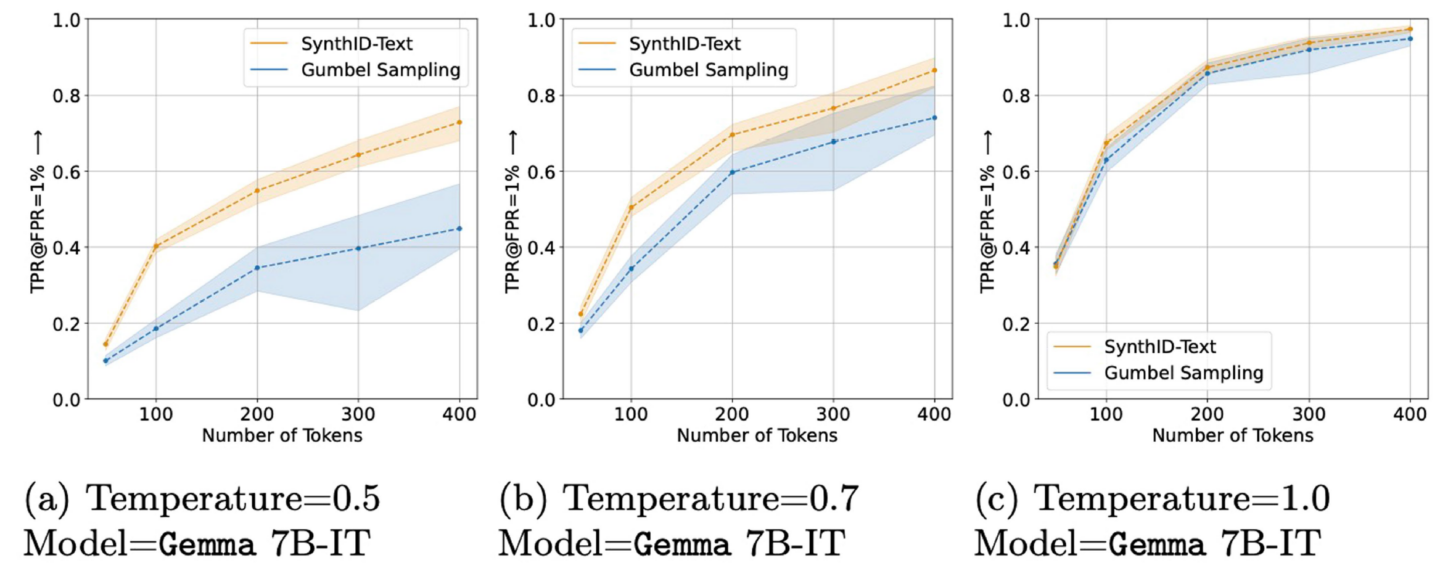
La investigación de Google muestra que SynthID es más confiable que otras herramientas de marcas de agua basadas en inteligencia artificial, pero su tasa de éxito depende en gran medida de la longitud y la entropía.
Las pruebas de Google también mostraron que su algoritmo de detección SynthID detectó con éxito texto generado por IA significativamente más que los esquemas de marcas de agua anteriores como Muestreo de apuestas. Pero el tamaño de esta mejora, y la velocidad general a la que SynthID puede detectar con éxito el texto generado por IA, depende en gran medida de la longitud y extensión del texto en cuestión. Establecer la temperatura Para el modelo de usuario. SynthID pudo detectar casi el 100 por ciento de las muestras de texto de 400 caracteres generadas por la IA del Gemma 7B-1T en 1.0, por ejemplo, en comparación con aproximadamente el 40 por ciento de las muestras de 100 caracteres del mismo patrón a temperatura 0.5. temperatura.